À la HEAR en 2021-2022 j’avais réalisé un système d’installation en temps réel qui cherchait notre sosie dans des images de visages générées par un algorithme de machine learning. Il cherchait dans une base de données d’images de visages (environ 200k) produits par l’algorithme StyleGAN2 de NVIDIA ThisPersonDoesNotExsit. Puis le programme sortait en output une impression des visages les plus ressemblant. J’avais réalisé des post de blog au début de ce projet accessible ici et là.
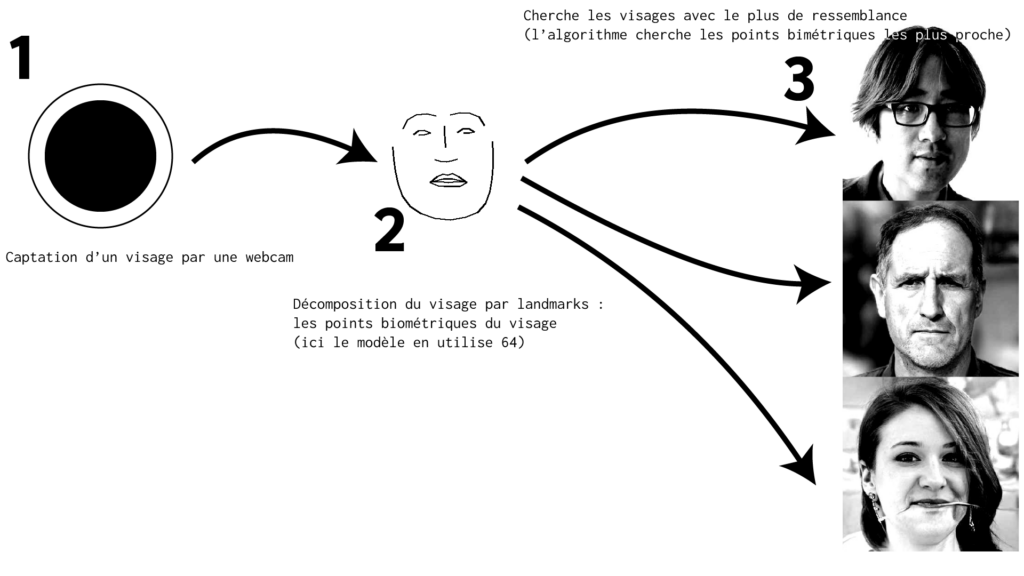
Il y avait toute une logique d’optimisation du programme notamment car il devait à priori être déployé sur un Raspi4 pour que l’imprimante thermique fonctionne. Le projet mettait aussi en exergue les limites de la reconnaissance faciale, les sosies trouvés sont relativement aléatoire. Et il y avait aussi par la sortie (l’impression sur ticket de caisse) une qualité d’image dégradé qui permettait mieux d’imaginer les ressemblances avec ces images.
Mais il traduit quelque part d’un intérêt pour une recontextualisation des images produites par un algorithme : on se compare à l’image produite, quel sont nos trait de ressemblances, nos différences. Que se passe t’il lorsque l’image sorti est très proche de notre visage ?
J’ai ensuite utilisé DALL•E v2 pour générer des sosies en partant d’images, principalement des selfies. En effet DALLE•E permet de générer une image, non pas à partir d’un prompt mais d’un image en input.
La recherche est finalement assez similaire, on ne demande plus à un algorithme de nous trouver des sosies générée, mais de générée des sosies. Mais quels sont les générations de visage les plus ressemblante pour l’algorithme ? Quel est mon meilleur faux sosie ?
J’ai donc réutilisé cet algo de reconnaissance faciale pour trouver les visages les plus proches de mon visage. Puis comment différencier les outputs, les classer, les cartographier ?
Avec l’algorithme de PCA (Principal Component Analysis), permettant ainsi de réduire les dimensions vectorielles des corpus, on donne à cet algorithme une liste de vecteurs à N-dimension (ici 128 dimensions), correspondant au points biométriques des visages, puis l’algorithme retourne cette même liste de vecteur à une dimension souhaité (ici 2 ou 3 pour représenter les vecteurs). Ainsi les visages à la biométrie « proche » (pour l’algorithme) vont se trouver proche dans ces cartographies de vecteurs.
L’algorithme de PCA est un algorithme de machine learning largement employé en science des données. On le retrouve notamment dans le cas du word embedding (mise en vecteur des mots), je l’ai par exemple utilisé pour ces continuations avec le word2vec.
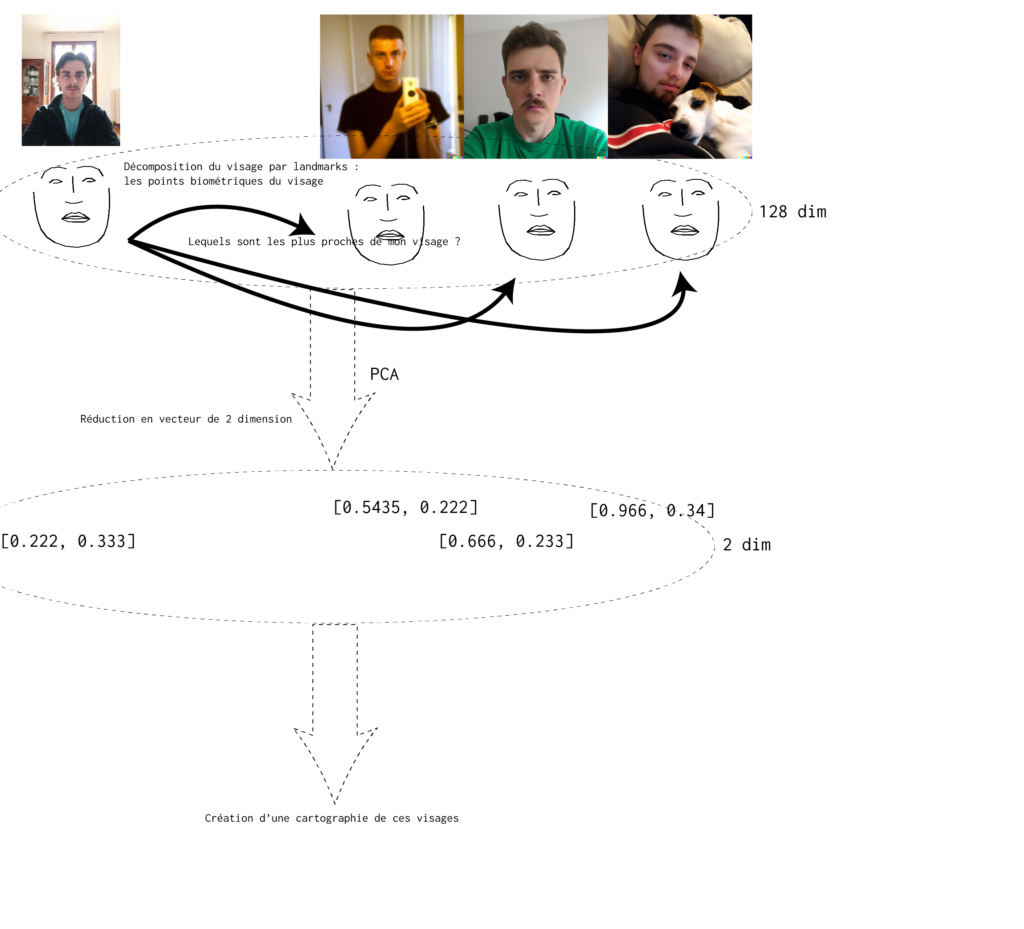
Grâce à ce pipeline d’algorithmes, on peut cartographier ces générations en fonctions des variations de leurs caractères biométriques. Où sont repartis ces visages, où est celui de référence par rapport aux autres ? Y a t’il des clusters, donc des zones où se repartissent plus les génération ? Donc est ce qu’il produit des visages au même trait donc a t’il un « type » dans sa génération ?
J’ai donc produit deux interfaces. une en 2d avec un système de cartographie et une interface 3d navigable en VR, (testé sur quest 2). Elles distribuent, les générations par rapport au calcul du PCA, et permet de différencier les outputs.
La version 2D est accessible ici.
La version VR est accessible ici.
De ces questionnement découle aussi d’autres pistes de recherche, Ces générations de visages sont t’elle plus ressemblante que les outputs de thispersonndoesnotexist ? Est-ce que des sosies sont plus ressemblant entre eux ?