Les générations d’images possible par des algorithmes de deep learning comme DALL•E v2 ou encore Stable diffusion peuvent être assez bluffantes, j’ai déjà réalisé quelques posts à ce sujets. Mais ces algo peuvent produire aussi beaucoup de ratés.

Ainsi ce meme m’a fait fait sourire et un petit peu réfléchir : l’algo montre ses limites sur des sujets complexes à représenter comme des mains / des mains se serrants. Pourquoi pas aller plus loin en lui demandant de redessiner des mains dans des plans existants ?
J’ai donc décider de produire un pipeline (schéma ci-dessous) qui depuis un flux vidéos va permettre de générer des mains. Il récupère ainsi un flux et pour chaque frame il va produire un masque en noir et blanc pour définir la zone ou se situe la main. Puis il envoie ces deux images à un algorithme de Inpainting qui va ainsi produire dans le masque une main « à sa sauce ». Ainsi il y a, à mon sens, plus de tension dans l’image que sur le meme : l’image est hybride et composée d’extrait photo et d’extrait « algorithme ». Ainsi ou est la limite du masque ? Qu’est-ce qui dans l’image apparaît « algorithmique » ?
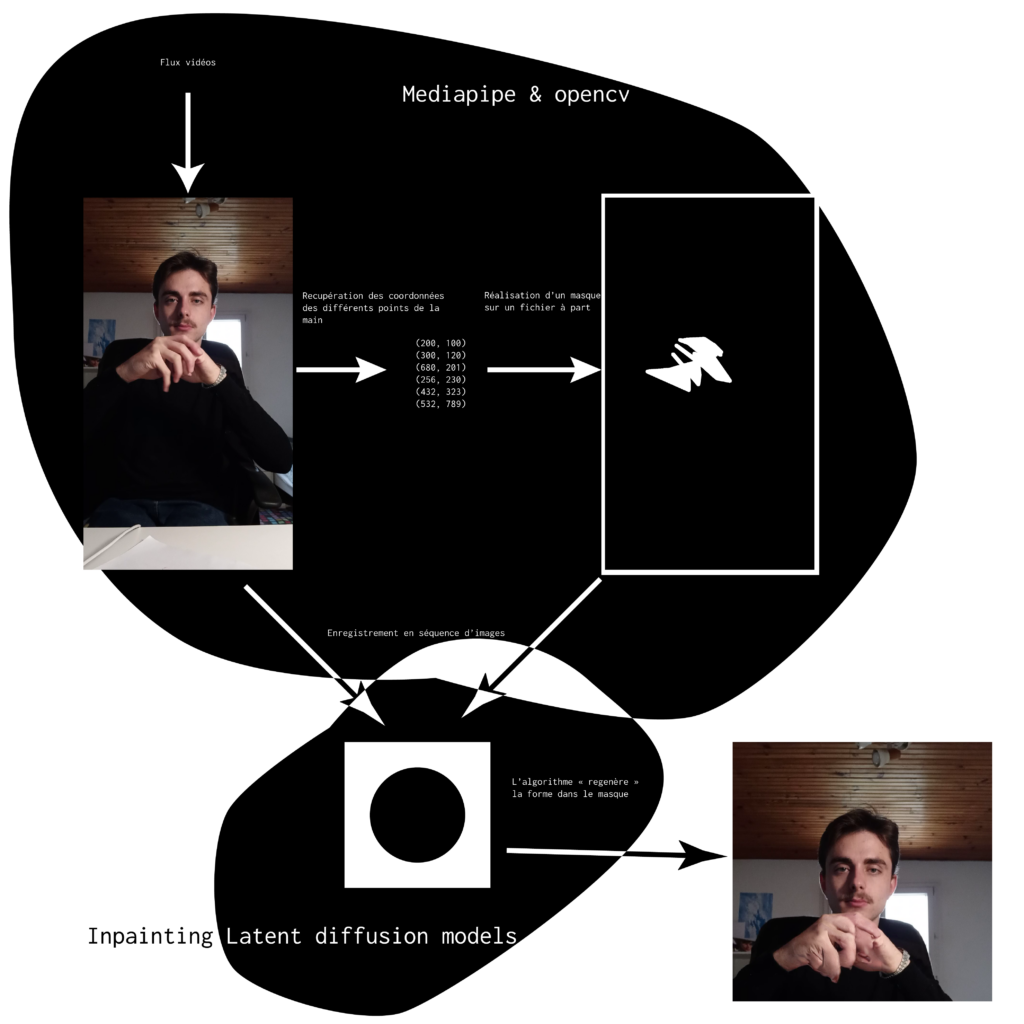
Les résultats présentés peuvent faire penser qu’il s’agit d’un algorithme en temps réel mais ce n’est pas le cas, la reconnaissance des mains s’effectue en temps réel mais la génération prend quelques secondes par frame. Il y a aussi un resizing de l’image avant de le passer dans l’algo d’inpainting. Le système peut potentiellement être en temps réel, mais il faudrait plus de puissance de calcul. Aussi les derniers modèles d’inpainting proposent aussi un text prompt pour mieux définir ce que l’on veut voir générer dans la zone masquée, ce qui pourrait avoir du potentiel pour décrire des sujets autres (sans doute une autre expérimentation à réaliser).